代码风格
print不换行、多输出无空格
println有换行,多输出有空格
printf格式化输出fmt.Printf("a=%v,b=%v,c=%v", a, b, c)
Printf%T打印变量类型fmt.Printf("a=%v,a的类型是%T",a,a)
行末不需要;
变量名称严格区分大小写
强制代码风格
go fmt xxx.go可以格式化代码
变量
声明变量:
//var 变量名称 变量类型
//var 变量名称
var username string;变量声明后必须使用 如果单独封装到一个包,变量名小写表示私有,大写表示共有 变量声明后没有初始化的话,值为空 变量不能为数字开头 变量名称不能使用关键词、保留字
初始化方式
//先声明再赋值
var username string
username = "张三"
//直接初始化
var username string = "张三"
//类型推导方式
var username = "张三"同一个作用域内不支持重复声明变量
一次定义多个变量
var a1,a2 string
a1 = "aaa"
a2 = "aaaaa"赋值类型必须和定义类型一致
一次多个类型不一致的变量
var (
username string
age int
sex string
)
// 声明时复制
var (
username string = "张三"
age int = 20
)
// 使用类型推导
var (
username = "张三"
age = 20
)短变量声名法
在函数内部,使用更简略的:=声明并初始化变量
// 类型推导
username := "张三"
// 一次多个变量
a,b,c := 12, 13, "aaa"只能生成局部变量
匿名变量
在使用多重赋值时,忽略某个值可以使用匿名变量
func getUserInfo() (string, int) {
return "张三", 10
}
func main() {
var username, age = getUserInfo()
fmt.Println(username, age)
//匿名变量,只取一个值
var _, age1 = getUserInfo()
fmt.Println(age1)
}常量
定义常量
const a = 1常量定义必须赋值 常量不能改变值 声明多个常量的方法和声明变量的方法一致
iota
iota是和常量一起使用的计数器,iota在const关键字出现时将被重置为0,const这种每新出现一次值+1
const (
a = iota //0
_ //可以插队
b //2
c //3
)- 多个iota可以定义在一行
const (
a, b = iota + 1, iota + 2 //1,2
c, d //3,4
)建议常量全部大写
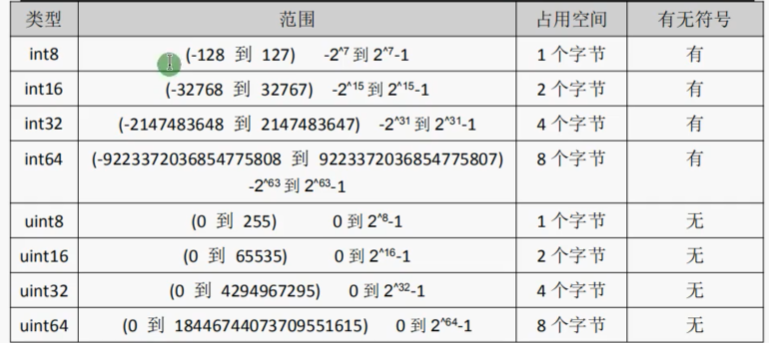
基本数据类型
int 整形
可以单独定义int8等等
默认值0
 1024字节=1kb
uintX 无符号整型
通过
1024字节=1kb
uintX 无符号整型
通过unsafe.Sizeof(xx)查看不同长度的整形,在内存里的存储空间
intX转intX,int64(a1)//把a1强制转换成64,高位向低位转换,要注意是否能放得下
数字字面量语法
特殊整形
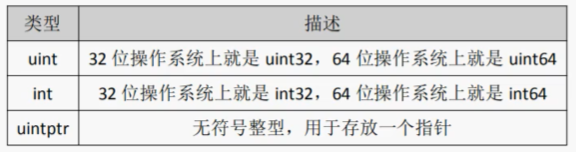 int在不同位数操作系统不一样,64就是int64,32就是int32
v表示原样输出,%d表示十进制输出,%b表示二进制输出,%o表示八进制输出,%x表示十六进制输出
int在不同位数操作系统不一样,64就是int64,32就是int32
v表示原样输出,%d表示十进制输出,%b表示二进制输出,%o表示八进制输出,%x表示十六进制输出
float浮点型
默认值0 Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准 float32的浮点数的最大范围约为3.4e38,可以使用常量定义:math.MaxFloat32。 float64的浮点数的最大范围约为1.8e308,可以使用一个常量定义:math.MaxFloat64。
%f可以格式化输出float
var c float64 = 3.1415926
// %.2f保留两位小数
fmt.Printf("%v--%f--%.2f",c,c,c)
//输出:
//3.1415926,3.141593,3.1464位系统默认定义float就是float64
科学计数法表示浮点
//3.14*10的2次方
var f2 float32 = 3.14e2
fmt.Printf("%v--%T",f2,f2)
//输出:
//314--float32
//3.14除以10的2次方
var f2 float32 = 3.14e-2精度丢失,使用第三方包解决(decimal)
类型转换(不建议float转int)
a := 10
b := float64(a)
fmt.Printf("a.类型是T%,b的类型是%T")
//输出int,float64 boolean类型
默认值false boolean不能参与类型转换、运算 true/false
string类型
默认值为空
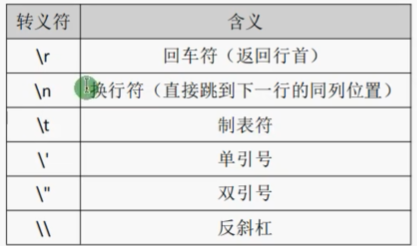
特殊符号
一次定义多行字符串(反引号)
str1 := `this is str
this is str
this is str
`len(str)获取字符串长度
var str1 = "你好"
fmt.Println(len(str1))
//输出:6(一个汉字占用3个长度)fmt.Sprintf拼接字符串
str1 := str1 + str2
//使用fmt.Sprintf()
str1 := "你好"
str2 := "golang"
str3 := fmt.Sprintf("%v %v",str1, str2)
fmt.Println(str3)
//输出 你好 golangstrings.Split分割字符串
var str1 = "123-456-789"
arr := strings.Split(str1,"-")
fmt.Println(arr)
//输出:[123 456 789]的切片strings.Join连接字符串
var str1 = "123-456-789"
arr := strings.Split(str1,"-")
str2 := strings.Join(arr,"*")
fmt.Println(str2)
//输出 123*456*789string.contains判断是否包含
str1 := "this is str"
str2 := "this"
flag := strings.contains(str1,str2)
fmt.Println(flag)
// 返回 truestrings.HasPrefix判断是否有前缀,strings.HasSuffix判断是否有后缀
str1 := "this is str"
str2 := "this"
flag = strings.HasPrefix(str1,str2)
// 输出 truestrings.index查询从前往后数索引,strings.LastIndex查询从后往前数索引(最后一次出现的索引)
查找不到返回-1
str1 := "this is str"
str2 := "s"
num := strings.LastIndex(str1,str2)
//输出:8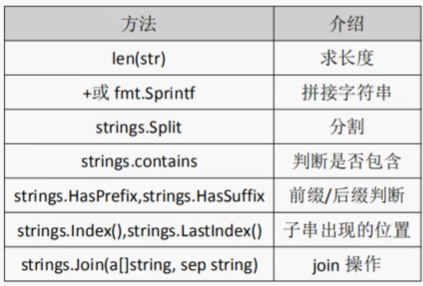
byte类型
字符
单引号一个字符定义字符var a = 'a'
字符属于int类型
字符分
- uint8类型,或者叫byte类型,代表一个ASCII码的字符
- rune类型,代表一个UTF-8字符
当需要处理中文、日文或者其他复合字符,需要用rune,rune类型实际是int32
go使用了特殊的rune类型来处理Unicode,让基于Unicode的文本处理更方便,也可以使用byte型进行默认字符串处理,性能和扩展性都有照顾
原样输出要用
%cgolang中汉字使用的是UTF-8编码,编码后的值就是int值,对应Unicode编码10进制
// 从字符串中输出字符
var str = "this"
fmt.Printf("值:%v,类型:%T,原样输出%c",str[2],str[2],str[2])
//输出:108,int8, i
var str1 = "this" // 占用4个字符
fmt.Println(unsafe.Sizeof(str1)) // 输出是16
// unsafe.Sizeof()没法查看string类型数据所占的存储空间
// 可以使用len(str)查看字节占用存储
// 通过循环输出字符串里的字符
s := "你好 golang"
for i := 0; i < len(s); i++ { //for循环使用byte类型
fmt.Printf("%v(%c)",s[i],s[i])
}
// 输出 228(ä)189(½)160( )229(å)165(¥)189(½)32( )103(g)111(o)108(l)97(a)110(n)103(g)
// 如果有汉字,输出的就有问题
// 使用range循环
s1 := "你好 golang"
for _, v := range s1{ //range循环使用rune
fmt.Printf("%v(%c)",v,v)
}
// 输出 20320(你)22909(好)32( )103(g)111(o)108(l)97(a)110(n)103(g)修改字符串
要修改字符串,需要先转换成[]rune或者[]byte,完成后再转换为string
无论哪种转换,都会重新分配内存,并复制字节数组
s1 := "big";
// 不能直接s1[0] = "p"修改
byteStr := []byte(s1)
byteStr[0] = 'p'
fmt.Println(string(byteStr))
// 有汉字需要用[]rune
s2 := "白萝卜"
runeStr := []rune(s2)
runeStr[0] = '黑'
fmt.Println(string(runeStr))基本数据类型转换
数值类型转换
建议低位转高位,高转低可能出现数据与预期不符
整形和浮点型
var a int8 = 20
var b int16 = 40
fmt.Println(int16(a)+b)
//转换成功,输出60(高转低)浮点型和浮点型
var a float32 = 20
var b float64 = 40
fmt.Println(float64(a)+b)
//转换成功,输出60(高转低)整形和浮点型
建议整形转float,不要float转整形,否则数据可能与预期不符
var a float32 = 20.23
var b int = 40
fmt.Println(a + float64(b))
//转换成功,输出60.23字符串转换-通过SPrintf
var i int = 20
str1 := fmt.SPrintf("%d",i)
fmt.Printf("%v--%T",str1)
//输出20,string格式化类型
| 格式化标识 | 介绍 |
|---|---|
| %% | %字面量 |
| %b | 一个二进制整数,将一个整数格式转化为二进制的表达方式 |
| %c | 一个Unicode的字符 |
| %d | 十进制整数 |
| %o | 八进制整数 |
| %x | 小写的十六进制数值 |
| %X | 大写的十六进制数值 |
| %U | 一个Unicode表示法表示的整型码值 |
| %s | 输出以原生的UTF8字节表示的字符,如果console不支持utf8编码,则会乱码 |
| %t | 以true或者false的方式输出布尔值 |
| %v | 使用默认格式输出值,或者如果方法存在,则使用类性值的String()方法输出自定义值 |
| %T | 输出值的类型 |
通过strconv进行转换
通过strconv把其他类型转换成string类型
var i int = 20
str1 := strconv.FormatInt(int64(i), 10) //参数1必须是int64,参数2是转换进制
fmt.Printf("%v-%T",str1,str1)
var f float32 = 20.23
/*
参数1:要转换的值 float64
参数2:格式化类型
'f'(-ddd.dddd)、
'b'(-ddddp±ddd,指数为二进制)、
'e'(-d.ddddetdd,十进制指数)、
'E'(-d.ddddE±dd,十进制指数)、
'g'(指数很大时用'e'格式,否则“f"格式)、
'G'(指数很大时用'E'格式,否则'f"格式)
参数3:保留的小数点-1(不对小数点格式
参数4:格式化的类型传入64 32
*/
str2 := strconv.FormatFloat(float64(f),'f',2,64)
fmt.Printf("%v-%T",str2,str2)
// 转换bool
str3 := strconv.FormatBool(true)
fmt.Printf("%v-%T",str3,str3)
// 转换byte
a := 'a'
str4 := strconv.FormatUnit(unit64(a),10)
fmt.Printf("%v-%T",str4,str4)string转int
str := "123456"
// 参数1:值,参数2:进制,参数3:64/32位数
num, _ := strconv.ParseInt(str, 10, 64)
num = num + 1
fmt.Printf("%v-%T", num, num)
// 输出7-int64string转float
str := "123456.78"
// 参数1:值,参数2:进制,参数3:64/32位数
flt, _ := strconv.ParseFloat(str, 64)
flt = flt + 1.2
fmt.Printf("%v-%T", flt, flt)
// 输出123457.98-float64bool类型转换
数值类型不能和bool类型互相转换 string转bool,不建议
b,_ := strconv.ParseBool("true")
fmt.Printf("%v-%T", b, b)
// 输出 true-bool
// 1和true为true,其他false语言运算符
算术运算符
+,-,*,/,%
除法注意:运算数都是整数的时候,相除后会去掉小数部分,保留整数
取余注意余数=被除数-(被除数/除数)x除数
自增++,自减--不属于算术运算符
自增自减
++,--只能独立使用
不能放在前面,只能放在后面
关系运算符
!=,>,>=,<,<=
逻辑运算符
&&,||,!
赋值运算符
+=,-=,*=,/=,%=
位运算符
&,|,^,<<,>>
流程控制
if else
if 表达式1{
分支1
} else if 表达式2{
分支2
} else {
分支3
}- if另一种写法
// age局部变量
if age := 34;age > 20{
fmt.Println("成年人)
}if {} 括号不能省略 {}括号必须紧挨着else或者else 条件
for
for i:=1; i<=10; i++{
fmt.Println(i)
}初始语句可以写在外面
i := 1
for ;i<=10; i++{
fmt.Println(i)
}go中没有while语句,用for替代
for true{
fmt.Println(1)
}for range(键值循环)
var str = "你好golang"
for k, v := range str {
fmt.Println("key=", k, "value=", v)
fmt.Printf("key=%v,val=%c\n",k,v)
}switch case
example := "abc";
switch example{
case "a":break
case "b":break
default:fmt.Println("default")
}break可以写也可以不写,建议写 一个分支可以有多个值 穿透fallthrough
var age = 30;
switch {
case age < 24:
fmt.Println("好好学习")
fallthrough
case age > 60:
fmt.Println("注意身体")
}
//输出
//好好学习,注意身体跳出/终止
break
用于循环跳出当前循环,开始执行循环之后的语句 break在switch中在执行一条case后跳出语句的作用 在多重循环中,可以用标号label标出想break的循环
label1:
for i := 0; i < 2; i++ {
for j := 0; j < 10; j++ {
fmt.Println("i=", i, "j=", j)
if j == 3 {
break label1
}
}
}continue
结束本次循环,开启下一次循环,仅循环内使用
label2:
for i := 0; i < 2; i++ {
for j := 0; j < 10; j++ {
fmt.Println("i=", i, "j=", j)
if j == 3 {
break label2
//直接跳到label2,继续执行外循环
}
}
}goto
跳转到指定标签
var n = 30
if n > 24 {
fmt.Println("成年人")
goto label3
// 跳到label3 不执行"aaa","bbb"
}
fmt.Println("aaa")
fmt.Println("bbb")
label3:
fmt.Println("ccc")
fmt.Println("ddd")集合
数组
数组是值类型,单独占用内存,不互相引用
// 声明数组
// 默认[0,0,0]
var arr [3]int
// 数组初始化
arr1[0] = 23
arr1[1] = 10
// 数组初始化 第二种方法 初始化的时候赋值
var arr2 = [3]int{3,4,5}
// 数组初始化 第三种方法 根据初始值自动推导数组长度
// 只能根据初始化的值数量推导长度,不能动态扩容
var arr3 = [...]int{4,5,6,7,8}
fmt.Println(len(arr3))//打印数组长度
// 指定数组下标
var arr4 = [...]int{0:1,2:30,99:5}多维数组
相当于数组嵌套
//一维数组
var arr = [int]3{1,2,3}
//二维数组
var arr2 = [3][2]string{
{"北京","上海"},
{"广州","深圳"},
{"成都","重庆"},
}
fmt.Println(arr2[0][1])
// 输出:上海切片
就是java中的集合 切片是引用类型,共用内存 切片是拥有相同类型元素的可变长度序列,是基于数组的一层封装,非常灵活,支持自动扩容 内部包含地址,长度,容量 len()获取长度(包含元素个数),cap()获取容量(从第一个元素开始数,到底层数组元素末尾的个数) 不能通过下表赋值方式给切片扩容
// 定义切片
var sli1 = []int{"php","java","nodejs","golang"}
// 基于数组定义切片
a := [5]int{55,66,77,88}
b := a[:] //获取数组里面所有值 也可以:a[1:4]截取1-4 a[2:]截取2到全部 a[:3]截取0-2
fmt.Printf("%v-%T",b,b)
//输出 [55 66 77 88 0]-[]int(无长度是切片)
// 基于切片的切片
c := []string{"北京","上海","广州","深圳"}
d := c[1:]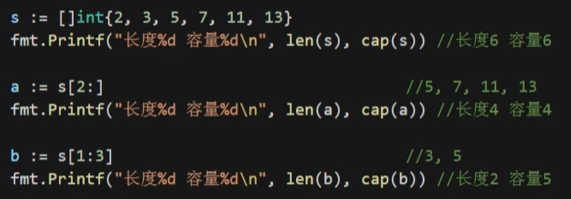
make函数、append()方法
var sliceA = make([]int,4,8) //长度,容量,默认数据全是0
// 追加数据(扩容)
sliceA = append(sliceA,12,24)//切片,数据
// 合并切片
var sliceB = []int{3,4,5}
sliceA = append(sliceA,sliceB...) //固定语法切片扩容策略
首先判断新申请容量大于2倍的旧容量,最终容量就是新申请的容量 否则判断如果旧切片长度小于1024,则最终容量就是就容量的两倍 否则判断如果旧切片长度大于1024,则最终容量从旧容量开十四循环增加原来的1/4,直到最终容量大于等于新申请的容量 如果最终容量计算值溢出,则最终容量就是新申请容量
copy函数
为引用类型复制一份新的
sliceA := []int{1,2,3,45}
sliceB := make([]int,4,4)
copy(sliceB,sliceA),/target,source
//此时改变切片副本不影响原切片切片中删除元素
go中没有直接删除元素的方法 通过append方法剔除元素
a := []int{30,31,32,33,34,35,36,37}
a = append(a[:2],a[3:]...)变量默认值
- 当声明一个变量,但却还并没有赋值时,golang会自动给你的变量赋值一个默认值
- bool → false
- numbers → 0
- string → ""
- pointers → nil
- slices → nil
- maps → nil
- channels → nil
- functions → nil
- interfaces → nil
切片排序
选择排序
选择最小数排到第一位,然后从其余数选出最小排到第二,以此类推
var numSlice =[]int{9,8,7,4,5,6}
// for循环对比然后换位
// 找到4,4和9换位置,然后从第二位到最后开始对比找冒泡排序
从头到尾,比较相邻的两个元素的大小,如果符合交换条件,交换两个元素位置 每轮比较,都会选出一个最大的数,放在正确的位置
sort排序
sort.Ints(slice)
sort.Float64s(slice)
sort.Strings(slice)
// 反转排序
sort.Sort(sort.Reverse(slice))map
map是引用类型 必须初始化后才能使用
// make创建map类型的数据
var userinfo = make(map[string]string,20)//[key]value 也可以不指定长度
userinfo["username"] = "张三"
userinfo["age"] = "20"
userinfo["sex"] = "男"
// 初始化填充变量
var userinfo2 = map[string]string{
"username": "张三",
"age": "20",
"sex": "男",
}遍历map
for k, v := range userinfo2 {
fmt.Println("key=", k, " value=", v)
}增删改查map
var userinfo2 = map[string]string{
"username": "张三",
"age": "20",
"sex": "男",
}
// 修改
userinfo2["username"] = "李四"
// 获取
fmt.Println(userinfo2["username"]) // 李四
// 查找
v, ok := userinfo2["age"]
fmt.Print("v=", v, "-ok=", ok, "\n") // 空,false
v, ok = userinfo2["xxx"]
fmt.Print("v=", v, "-ok=", ok) // 20,true
// 删除
delete(userinfo2, "sex")
fmt.Print(userinfo2) // 没有sex
map切片
var userinfoSlice = make([]map[string]string, 2, 2)
var userinfo = map[string]string{
"username": "张三",
"age": "20",
"sex": "男",
}
userinfoSlice = append(userinfoSlice, userinfo)
userinfoSlice[1] = make(map[string]string)
userinfoSlice[1]["username"] = "李四"
userinfoSlice[1]["age"] = "45"
userinfoSlice[1]["sex"] = "女"
fmt.Print(userinfoSlice)map数据的值可以是切片
排序
map1 := make(map[int]int)
map1[10] = 100
map1[16] = 200
map1[12] = 600
var slice1 []int
for k := range map1 {
slice1 = append(slice1, k)
}
sort.Ints(slice1)
map2 := make(map[int]int)
for _, i := range slice1 {
map2[i] = map1[i]
}
fmt.Println(map2)
// 10,12,16函数
// x,y int 表示两个数据类型一样
func sumFn(x,y int) int {
sum := x+y
return sum
}
func main(){
sum := sumFn(12,3)
}可变参数x int,y ...int
可以有多个返回值(int,int),明明返回值a int,b int
定义函数类型
- 函数类型的%T是
类包.类型名 - 函数类型如果用推导,则直接是
func(xx) xx
package main
import "fmt"
// 定义一个calc的类型
type calc func(int, int) int
func add(x, y int) int {
return x + y
}
// 方法作为方法参数
func other(x int,cb func(int,int) int,cb1 calc) int{
cb(x,x)
cb1(x,x)
return 1;
}
func main() {
var c1 calc = add
fmt.Println(c1(1, 2)) // 3
fmt.Printf("%T", c1) // main.calc
fmt.Println()
c2 := add
fmt.Printf("%T", c2) // func(int, int) int
// 匿名函数
j := other(2, func(i int, i2 int) int {
return i - i2
}, add)
fmt.Println(j)
}也可以自定义类型定义别的类型type myInt int
type myInt int
func main() {
var i1 myInt = 1
var i2 int = 2
fmt.Printf("i1Type=%T,i2Type=%T", i1, i2) // i1Type=main.myInt,i2Type=int
// 要使用类型转换
i2 = int(i1)
i1 = myInt(i2)
}
函数不能嵌套,只能定义匿名方法(没有名称)
递归
func fn2(n int) int{
if n > 1{
return n + fn2(n - 1)
}else {
return 1
}
}变量作用域
全局变量
定义在函数外,程序整个运行周期内都有效 污染全局
局部变量
定义在函数内,函数内定义的变量无法在函数外使用 不会污染全局
闭包
闭包是指有权访问另一个函数作用域中的变量的函数 创建闭包的常见的方式是在一个函数内部创建另一个函数,通过另一个函数访问这个函数的局部变量 这个变量既常驻内存,又不污染全局
func addr() func(int) int {
var i = 10
return func(y int) int {
// i 虽然是局部变量,但是相对于本方法是全局变量
// 进行赋值,会改变这个变量的全局值
i += y
return i
}
}
func main() {
var a = addr()
fmt.Println(a(10))
fmt.Println(a(10))
fmt.Println(a(10))
}defer延迟处理
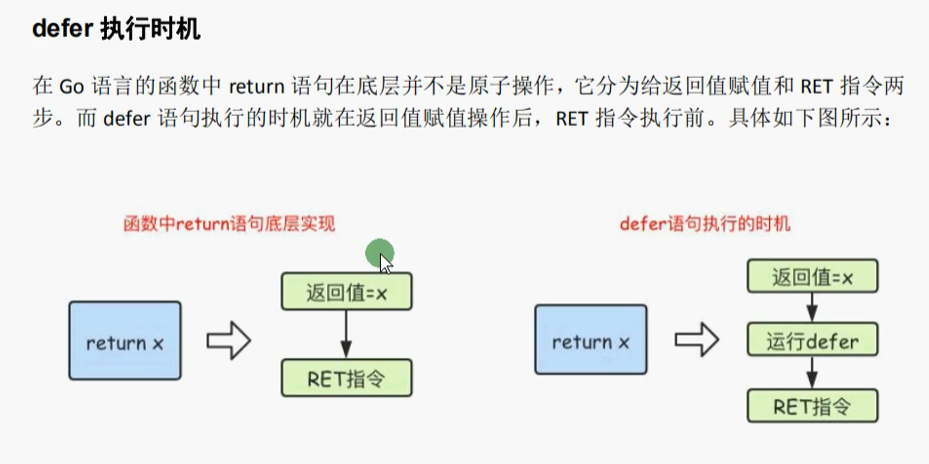
defer语句会将其后面跟随的语句进行延迟处理。在defer归属函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句最先被执行
func main() {
fmt.Println("开始")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("结束")
// 输出 3,2,1
}关于匿名返回值
先给返回值赋值,再defer,再返回
如果是匿名返回值,定义a,那么在defer之前a的默认值0就赋值给了返回值,defer语句只是修改了你定义的a,并没有修改返回值,所以a=0
如果是命名返回值,返回a,那么在defer的时候修改的就是返回值的值,所以a=1
func f1() int {
var a int
defer func() {
a++
}()
return a
}
func f2() (a int) {
defer func() {
a++
}()
return a
}
func main() {
fmt.Println(f1()) //0
fmt.Println(f2()) //1
}defer要执行的func的参数会被先执行,或者说先记录参数是多少
panic抛出异常,recover()捕获异常
程序遇到panic会结束程序抛出异常 panic可以在任何地方引发,但recover只能在defer调用的函数中有效
func fn2() int {
defer func() {
err := recover()
if err != nil {
fmt.Println(err)
}
}()
panic("异常")
return 1
}
func main() {
fmt.Println(fn2())
//输出:异常,0(int默认值)
}时间
time包 %02d补0
package main
import (
"fmt"
"time"
)
func main() {
var timeObj = time.Now()
year := timeObj.Year()
month := timeObj.Month()
day := timeObj.Day()
hour := timeObj.Hour()
min := timeObj.Minute()
sec := timeObj.Second()
fmt.Printf("%d-%d-%d-%d-%d-%d", year, month, day, hour, min, sec)
fmt.Println()
fmt.Printf("%02d-%02d-%02d %02d:%02d:%02d", year, month, day, hour, min, sec)
//必须是2006-01-02
//时:03=12小时制度,15=24小时制
//04:05
str := timeObj.Format("2006-01-02 15:04:05")
fmt.Println()
fmt.Println(str)
}获取当前时间戳
package main
import (
"fmt"
"time"
)
func main() {
timeObj := time.Now()
// 当前时间戳
fmt.Println(timeObj.Unix())
// 纳秒时间戳
fmt.Println(timeObj.UnixNano())
}
时间戳转日期字符串
package main
import (
"fmt"
"time"
)
func main() {
timeObj := time.Now()
unixTime := timeObj.Unix()
timeObj1 := time.Unix(unixTime,0)//int64类型,第一个是毫秒,第二个是纳秒,不用就写0
fmt.Println(timeObj1.Format("2006-01-02 15:04:05"))
}
字符串转日期
package main
import (
"fmt"
"time"
)
func main() {
var str = "2025-03-23 15:34:12"
timeObj,_ := time.ParseInLocation("2006-01-02 15:04:05",str,time.Local) //还会接收error
fmt.Println(timeObj)
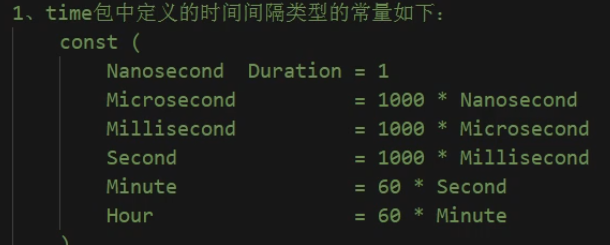
}时间间隔常量
时间操作函数
package main
import (
"fmt"
"time"
)
func main() {
fmtStr := "2006-01-02 03:04:05"
var timeObj = time.Now()
fmt.Println(timeObj.Format(fmtStr))
// 增加时间
timeObj1 := timeObj.Add(time.Hour)
fmt.Println(timeObj1.Format(fmtStr))
}
定时器
使用Ticker
package main
import (
"fmt"
"time"
)
func main() {
// 执行定时器
ticker := time.NewTicker(time.Second)
i := 0
for t := range ticker.C {
if i == 5 {
// 终止定时器
ticker.Stop()
break
}
fmt.Println(t)
i++
}
}使用time.Sleep()
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("aaa")
time.Sleep(time.Second) //休眠一秒钟
fmt.Println("bbb")
fmt.Println("ccc")
}
指针
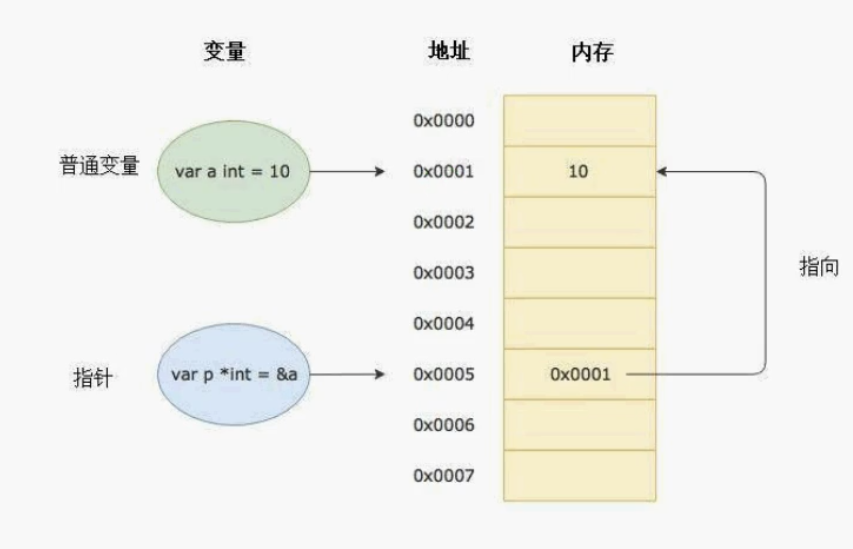 在计算机底层,a这个变量对应了一个内存地址
在计算机底层,a这个变量对应了一个内存地址
package main
import "fmt"
func main() {
var a int = 10
fmt.Printf("a=%v,aType=%T,a地址=%p",a,a,&a)
}指针类型和变量类型是11对应的 所有变量都有内存地址,包括指针变量
package main
import (
"fmt"
)
func main() {
var a = 10
var b = &a
fmt.Printf("a=%v,aType=%T,a地址=%p", a, a, &a)
fmt.Println()
fmt.Printf("a=%v,aType=%T,a地址=%p", b, b, &b)
fmt.Println()
fmt.Println(*b) //*b表示取出或者改变变量对应的内存地址的实际值
}
new函数分配内存

package main
import "fmt"
func main() {
var a = new(int)
var b = new(bool)
fmt.Printf("%v-%T-%v", a, a, *a)
fmt.Println()
fmt.Printf("%v-%T-%v", b, b, *b)
}
make函数分配内存
make只能用于slice、map、channel的初始化,返回的还是这三个引用类型本身,而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针
go结构体
go中的类,是值类型
结构体大写开头表示公有
结构体小写开头表示私有
go中支持对结构体指针直接使用来访问结构体成员,比如p2.name = 李四,在底层是(*p2).name
type 类型名 struct {
字段名 字段类型
字段名 字段类型
...
}实例化结构体
package main
import "fmt"
// 结构体大写开头表示公有
// 结构体小写开头表示私有
type Person struct {
name string
age int
sex string
}
func main() {
var p1 Person //实例化结构体,类型是声明类型
p1.name = "张三"
p1.sex = "男"
p1.age = 24
fmt.Println(p1)
fmt.Printf("%#v", p1) //%#V结构体详细信息
fmt.Println()
//第二种实例化方法,类型是指针类型
var p2 = new(Person)
p2.name = "李四"
p2.sex = "女"
p2.age = 28
fmt.Printf("%#v", p2) //%#V结构体详细信息
fmt.Println()
//第三种,类型是指针类型
var p3 = &Person{}
p3.name = "王五"
p3.sex = "沃尔玛购物袋"
p3.age = 78
fmt.Printf("%#v", p3) //%#V结构体详细信息
fmt.Println()
// 第四种直接实例化,使用type就是声明类型,使用&type是指针类型
// 可以不给某个属性赋值,就是数据类型默认值
var p4 = Person{
name: "老六",
age: 109,
}
fmt.Printf("%#v", p4) //%#V结构体详细信息
fmt.Println()
// 可以不写key,但是必须顺序对应
var p5 = Person{
"七酱",
77,
"男",
}
fmt.Printf("%#v", p5) //%#V结构体详细信息
}
给结构体增加方法
给自定义类型也是这么加
package main
import "fmt"
type Person struct {
name string
age int
sex string
}
// 如果需要修改结构体属性值,需要传入指针类型,即*type
func (p *Person) Walk() {
p.name = "张三(plus)"
fmt.Println(p.name, "在走路")
}
func main() {
p1 := Person{
name: "张三",
}
p1.Walk()
fmt.Println(p1.name)
}
匿名字段,结构体匿名属性声明,字段类型不能重复
type Person struct {
string
int
}结构体嵌套
package main
import "fmt"
type Person struct {
Name string
Age int
Hobby []string
map1 map[string]string
Address
// 也可以起名字 Ad Address
}
type Address struct {
Name string
FullName string
}
func main() {
var p1 Person
p1.Name = "张三"
p1.Age = 12
p1.Hobby = make([]string, 6, 6)
p1.Hobby[0] = "写代码"
p1.Hobby[0] = "打游戏"
p1.map1 = make(map[string]string)
p1.map1["地址"] = "上海"
// 嵌套结构体赋值,直接点
p1.Address.Name = "上海"
// 可以省略,需要上文直接使用Address省略属性名
p1.FullName = "中国上海"
fmt.Printf("%#v", p1)
fmt.Println()
fmt.Println(p1.Hobby)
}
结构体继承
就是直接嵌套 结构体嵌套可以包含另一个结构体的指针,这种方式可以让多个主结构体实例共用一个指针的嵌套结构体
package main
import "fmt"
type Animal struct {
Name string
}
func (a Animal) run() {
fmt.Println(a.Name, "跑")
}
type Dog struct {
Jiaosheng string
Animal
}
func (d Dog) Jiao() {
fmt.Println(d.Name, d.Jiaosheng)
}
func main() {
dog := Dog{
Jiaosheng: "wo owow o",
Animal: Animal{Name: "小汪"},
}
dog.run()
dog.Jiao()
}
结构体序列化json字符串,属性必须首字母大写(首字母大小表示公有)
package main
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int
Name string
Sex string
}
func main() {
stu := Student{
ID: 1,
Name: "张三",
Sex: "男",
}
fmt.Printf("%#v", stu)
fmt.Println()
jsonByte, _ := json.Marshal(stu) // 返回byte切片
jsonStr := string(jsonByte)
fmt.Println(jsonStr)
}
json字符串转结构体
package main
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int
Name string
Sex string
}
func main() {
str := `{"ID":1,"Name":"张三","Sex":"男"}`
var stu Student
error := json.Unmarshal([]byte(str), &stu)
if error != nil {
fmt.Println(error)
} else {
fmt.Printf("%#v", stu)
}
}
结构体标签tag,这样转成json就会用标签里的值,或者从json反转,可以用于首字母大小写转换
type Student struct {
ID int `json:"id"`
Name string `json:"name"`
Sex string `json:"sex"`
}包
包是多个go源码集合,代码复用方案,有很多内置包:fmt、strings等等 自定义包,新建文件夹下xxx.mod,import引入包 一个文件夹下的packge只能归属于一个packge 一个项目只能有一个main.go
package main
import C "go_demo/calc" //也可以给包取别名
import _ "xxx/xxx" //匿名引用
import (
"fmt"
)
func main() {
// fmt.Println(calc.Add(1, 2))
fmt.Println(C.Add(12, 2))
}
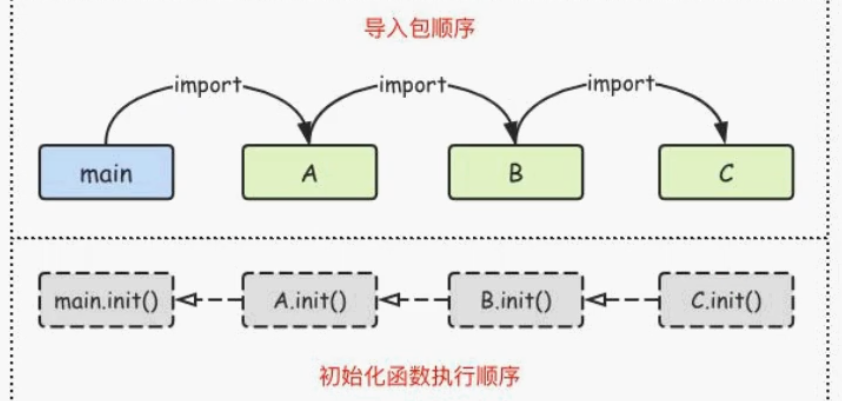
包引用顺序,先执行最后引入的A
 第三方包
初始化go.mod
第三方包
初始化go.modgo mod init 项目名
下载包
- go mod tidy 删除不需要的包,下载需要的包
- go get xxxx 下载包
接口(interface)
抽象类型 建议接口文件名+er表示是接口 如果接口里面有方法,必须要通过结构体或者通过自定义类型来实现这个接口 接口是规范,只是用约定
type 接口名 interface{
方法名1(参数列表) 返回值列表1
...
}package main
import "fmt"
type Usber interface {
start()
stop()
}
type Phone struct {
Name string
}
func (p Phone) start() {
fmt.Println("start方法:启动")
}
func (p Phone) stop() {
fmt.Println("start方法:启动")
}
func main() {
p := Phone{
Name: "华为",
}
p.start()
var p1 Usber //golang中接口是一种数据类型
p1 = p //表示p实现Usber接口
p1.start()
}接口可以不定义任何方法,没有定义任何方法的接口就是空接口。空接口表示没有任何约束
可以用空接口表示任意数据类型
func show(a interface[]){
//xxx
}类型断言
一个接口的值(简称接口值)是由一个具体类型和具体类型的值两部分组成,这两部分分别成为接口的动态类型和动态值
如果想要判断空间中值的类型,那么这个时候可以使用类型断言:x.(T)
x表示interface{变量
T表示断言x可能是的类型
package main
import "fmt"
func main() {
var a interface{}
a = "你好golang"
v, ok := a.(string) // ok=true表示断言正确
fmt.Println(v, ok)
}
结构体值指针接收只能用指针实例化对象赋值给接口
package main
import "fmt"
type Animaler interface {
SetName(string)
GetName() string
}
type Bionter interface {
SetName(string)
GetName() string
}
type Dog struct {
Name string
}
func (d *Dog) SetName(name string) {
d.Name = name
}
func (d Dog) GetName() string {
return d.Name
}
func main() {
dog1 := &Dog{
Name: "图图",
}
var anm1 Animaler = dog1
fmt.Println(dog1.GetName())
anm1.SetName("八公")
fmt.Println(anm1.GetName())
// 一次实现多个接口
var biot1 = dog1
fmt.Println(biot1.GetName())
}
接口嵌套
package main
import "fmt"
type A interface {
run()
}
type B interface {
walk()
}
type Animaler interface {
SetName(string)
GetName() string
A
B
}
type Dog struct {
Name string
}
func (d *Dog) SetName(name string) {
d.Name = name
}
func (d Dog) GetName() string {
return d.Name
}
func (d Dog) run() {
fmt.Println(d.GetName(), "run")
}
func (d Dog) walk() {
fmt.Println(d.GetName(), "walk")
}
func main() {
dog1 := &Dog{
Name: "图图",
}
var anm1 Animaler = dog1
fmt.Println(dog1.GetName())
anm1.SetName("八公")
fmt.Println(anm1.GetName())
anm1.run()
}
空接口访问目标类型索引、属性
package main
import "fmt"
type Address struct {
FAddress string
}
func main() {
var userinfo = make(map[string]interface{})
userinfo["username"] = "张三"
userinfo["age"] = 20
userinfo["hobby"] = []string{"吃饭", "睡觉"}
adr := Address{
"地球",
}
userinfo["address"] = adr
fmt.Println(userinfo)
// 空接口不能访问下标
//userinfo["hobby"][0]
// 通过断言访问
v, ok := userinfo["hobby"].([]string)
if ok {
fmt.Println(v[0])
}
// 空接口不能访问结构体属性
//fmt.Println(userinfo["address"].FAddress)
// 通过断言访问
v2, ok2 := userinfo["address"].(Address)
if ok2 {
fmt.Println(v2.FAddress)
}
}
goroutine<协程>
golang协程是用户级别的,占用内存更少,是相比其它语言的优势
package main
import (
"fmt"
"time"
)
func test() {
for i := 0; i < 10; i++ {
fmt.Println("test()你好golang")
time.Sleep(time.Millisecond * 1000)
}
}
func main() {
go test() //开启一个协程
for i := 0; i < 10; i++ {
fmt.Println("main()你好golang")
time.Sleep(time.Millisecond * 1000)
}
}
主线程执行完毕,协程不管有没有执行完也会退出
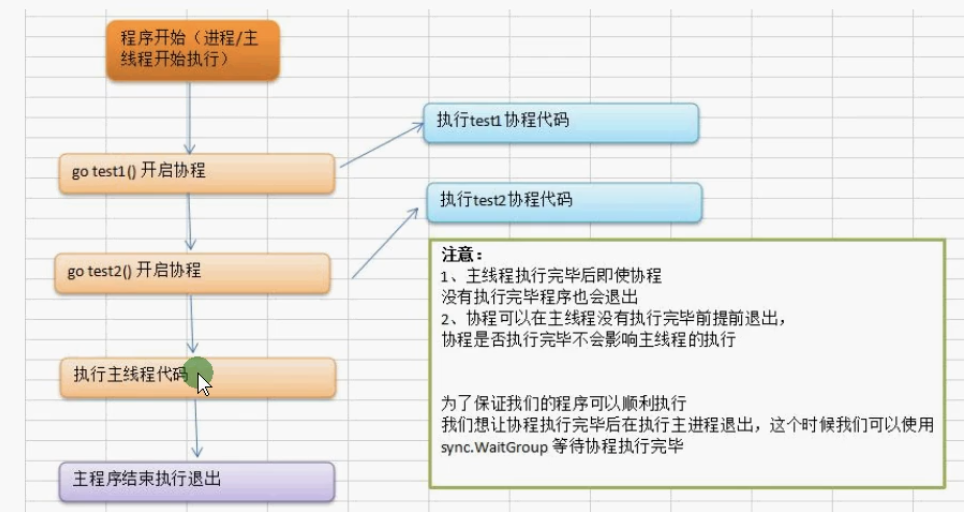
使用sync.WaitGroup实现等待协程执行完毕
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func test() {
for i := 0; i < 10; i++ {
fmt.Println("test()你好golang-", i)
time.Sleep(time.Millisecond * 1000)
}
wg.Done()
}
func main() {
wg.Add(1) // 可以开启多个
go test() //开启一个协程
for i := 0; i < 10; i++ {
fmt.Println("main()你好golang-", i)
time.Sleep(time.Millisecond * 500)
}
wg.Wait()
}
设置CPU数量
默认使用电脑上所有CPU
使用runtime.GOMAXPROCS()设置当前程序并发时占用的CPU逻辑核心数
1.5之前是单核执行
多协程并行
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
var wg = sync.WaitGroup{}
func test(num int) {
defer wg.Done()
for i := 0; i <= 5; i++ {
fmt.Printf("\n协程(%v)打印的第%v条数据", num, i)
time.Sleep(time.Millisecond * 500)
}
}
func main() {
// 获取主机CPU个数
fmt.Println(runtime.NumCPU())
for i := 0; i < 6; i++ {
wg.Add(1)
go test(i)
}
wg.Wait()
fmt.Println()
fmt.Println("关闭主线程")
}
channel<管道>
管道是提供给goroutine间的通讯方式,可以在多个协程之间传递消息 是一种数据类型,引用数据类型 多个协程之间共享管道数据 总是遵循先入先出,保证收发数据顺序 管道的值就是数据地址
创建管道
make(chan 元素类型,容量)
管道操作
发送:ch <- 10 把10发送到ch中
接收:x := <- ch从ch中接收并赋值给x
package main
import "fmt"
func main() {
ch := make(chan int, 3)
ch <- 10
fmt.Println(<-ch)
// 取不出来,报错↓
fmt.Println(<-ch)
}
管道阻塞
管道放不下数据的时候就开始阻塞 管道没有值了继续取值也会阻塞(没有使用协程的情况下)
关闭管道ch.close()
建议写入数据后关闭管道
循环遍历管道
package main
import "fmt"
func main() {
ch := make(chan int, 10)
for i := 0; i < 10; i++ {
ch <- i
}
// 使用 for i循环管道,管道可以不关闭
for i := 0; i < 10; i++ {
fmt.Println(<-ch)
}
// 使用for range循环遍历管道,写入数据后,必须关闭管道,否则死锁
close(ch)
for i := range ch {
fmt.Println(i)
}
}
协程结合管道
管道是安全的,读取管道会等待管道写入
package main
import (
"fmt"
"sync"
"time"
)
var wg = sync.WaitGroup{}
func insert(ch chan int) {
defer wg.Done()
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("写入", i)
time.Sleep(time.Second * 2)
}
}
func read(ch chan int) {
defer wg.Done()
for i := 0; i < 10; i++ {
fmt.Println("读取", <-ch)
time.Sleep(time.Second)
}
}
func main() {
var ch = make(chan int, 10)
wg.Add(1)
go insert(ch)
wg.Add(1)
go read(ch)
wg.Wait()
fmt.Println("结束")
}
多线程找质数
44 Go语言 goroutine channe(四) | 29:47
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func putNum(intChan chan int) {
defer wg.Done()
for i := 2; i < 1200000; i++ {
intChan <- i
}
close(intChan)
}
func primeNum(intChan chan int, primeChan chan int, extChan chan bool) {
for num := range intChan {
if num > 1 {
var flag = true
for j := 2; j < num; j++ {
if num%j == 0 {
flag = false
break
}
}
if flag {
primeChan <- num
}
}
}
extChan <- true
wg.Done()
}
func printPrime(primChan chan int) {
defer wg.Done()
for i := range primChan {
fmt.Print(i, ",")
}
}
func main() {
start := time.Now().Unix()
intChan := make(chan int, 1000)
primeChan := make(chan int, 1000)
extChan := make(chan bool, 16)
wg.Add(1)
go putNum(intChan)
for i := 0; i < 16; i++ {
time.Sleep(time.Millisecond * 10)
wg.Add(1)
go primeNum(intChan, primeChan, extChan)
}
wg.Add(1)
// 判断exitChan是否存满
go func() {
for i := 0; i < 16; i++ {
<-extChan
}
close(primeChan)
wg.Done()
}()
wg.Add(1)
go printPrime(primeChan)
wg.Wait()
end := time.Now().Unix()
fmt.Println("执行完毕,用时", end-start)
}
单向管道
45 Go语言 goroutine channe 单向管道、select多路复用、goroutine panic处理(五) | 27 可以用于给方法管道参数规定只能读取或者写入
package main
func main() {
// chan<- 只写管道
ch1 := make(chan<- int, 2)
ch1 <- 12
// <-chan 只读管道
ch2 := make(<-chan int, 2)
}
select 多路复用
45 Go语言 goroutine channe 单向管道、select多路复用、goroutine panic处理(五) | 08:55 select类似switch语句,有一系列分支和一个默认分支 每个case会对应一个管道的通信过程 select会一直等待,直到某个case的通信操作完成,就会执行case对应的语句 不需要关闭通道,defualt:return就可以 主要解决:在某些场景需要同时从多个通道获取数据
package main
import "fmt"
func main() {
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
for {
select {
case v := <-intChan:
fmt.Printf("从 intChan 读取的数据%v\n", v)
case v := <-stringChan:
fmt.Printf("从 stringChan 读取的数据%v\n", v)
default:
fmt.Printf("数据读取完毕")
return
}
}
}gorountine中解决协程出现的panic
45 Go语言 goroutine channe 单向管道、select多路复用、goroutine panic处理(五) | 14:48
package main
import (
"fmt"
"sync"
)
var wg = sync.WaitGroup{}
func test1() {
fmt.Println("协程1")
wg.Done()
}
func test2() {
defer func() {
if err := recover(); err != nil {
fmt.Println("程序员异常", err)
wg.Done()
}
}()
var map1 map[string]string
map1["0"] = "1"
wg.Done()
}
func main() {
wg.Add(1)
go test1()
wg.Add(1)
go test2()
wg.Wait()
}
并发安全和锁
46 Go语言 goroutine互斥锁 读写互斥锁(六) | 16
互斥锁
互斥锁是传统并发编程中对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
var count = 0
var mutex sync.Mutex
func test() {
// 加锁/等待解锁
mutex.Lock()
count++
fmt.Println("count=", count)
time.Sleep(time.Microsecond)
// 解锁
mutex.Unlock()
wg.Done()
}
func main() {
for r := 0; r < 20; r++ {
wg.Add(1)
go test()
}
wg.Wait()
}读写互斥锁
46 Go语言 goroutine互斥锁 读写互斥锁(六) | 12:20
互斥锁的本质是一个goroutine访问的时候,其他goroutine都不能访问。这样在资源同步,避免竞争的同时也降低了程序的并发性能。程序由原来的并行变成串行
其实只做读操作的话,不存在资源竞争问题,所以问题主要是修改上
因此出现另一种锁,叫读写锁
读写锁可以让多个读操作并发,同时读取,但是对于写操作是完全互斥的,也就是说,当一个goroutine进行写操作的时候,其他goroutine既不能进行读操作,也不能进行写操作
读写互斥锁使用sync.RWMutex
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
var count = 0
var mutex sync.RWMutex
func write() {
mutex.Lock()
fmt.Println("执行写操作")
time.Sleep(time.Second)
mutex.Unlock()
wg.Done()
}
func read() {
mutex.RLock()
fmt.Println("---执行读操作")
time.Sleep(time.Second)
mutex.RUnlock()
wg.Done()
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1)
go read()
}
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
wg.Wait()
}
反射
47 Go语言 反射 反射的引出、反射获取变量类型变量值、反射修改变量值 | 33 有时候我们需要写一个函数,这个函数有能力统一处理各种值得类型,而这些类型可能无法共享同一个接口, 也可能布局未知,也有可能这个类型在我们设计函数得时候还不存在,这个时候我们就可以用到反射
反射是指程序在运行期间对程序本身进行访问和修改得能力。正常情况程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分。在运行程序时,程序无法获取自身得信息。支持反射的语言可以在程序编译期将变量的反射信息,如字段名称、类型信息、结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,这样就可以在程序运行期间获取类型的反射信息,并且有能力修改它们。
反射可以实现
- 在程序运行期间动态获取变量信息,比如变量的类型,类别
- 如果是结构体,通过反射还可以获取结构本身的信息,比如结构体的字段、结构体的方法
- 通过反射,可以修改变量的值,可以调用关联的方法
- Go中的变量分为两部分
- 类型信息:预先定义好的元信息
- 值信息:程序运行过程中可动态变化的
在go的反射机制中,任何接口值都是由一个具体类型和具体类型的值练鼓部分组成的
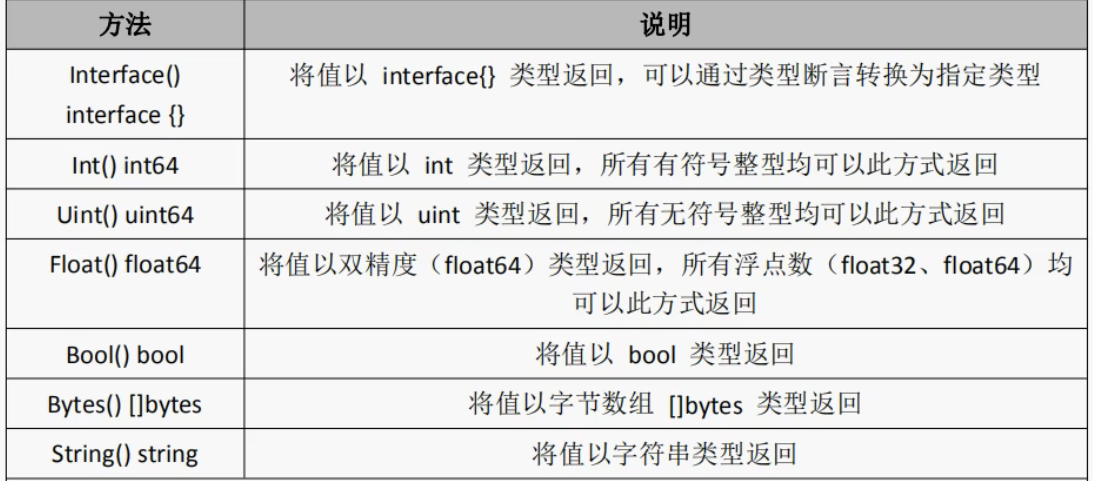
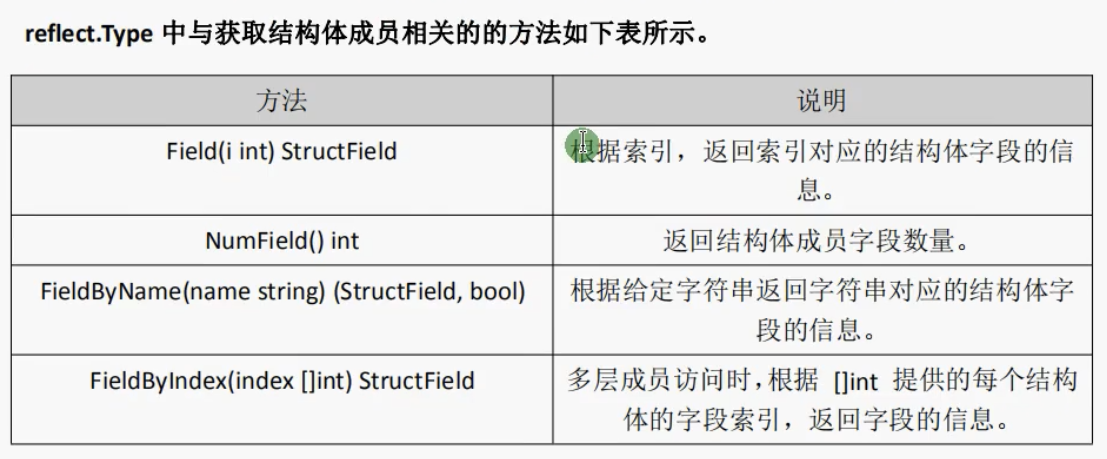
在go中反射的相关功能由内置的reflect报提供,任意接口值在反射中都可以理解为由reflect.Type和reflect.Value两部分组成,并且reflect包提供了reflect.TypeOf和reflect.ValueOf两个重要函数来获取任意对象的Value和Type
type Name和type Kind
在反射中关于类型还划分为两种:类型(Type)和种类(Kind)。因为在Go语言中我们可以使用type关键字构造很多自定义类型,而种类(kind)就是指底层的类型,但在反射中,当需要区分指针、结构体等大品种的类型时,就会用到种类(Kind)。举个例子,我们定义了两个指针类型和两个结构体类型,通过反射查看它们的类型和种类。
Go语言的反射中像数组、切片、Map、指针等类型的变量,它们的.Name()都是返回空。
package main
import (
"fmt"
"reflect"
)
type myInt int
type Person struct {
Name string
Age int
}
func reflectFn(x interface{}) {
v := reflect.TypeOf(x)
fmt.Println("直接打印", v)
fmt.Println("v.Name=", v.Name())
fmt.Println("v.Kind=", v.Kind())
fmt.Println("---")
}
func main() {
a := 10
b := "nihao"
c := true
d := 23.45
var e myInt = 10
f := Person{
Name: "张三",
Age: 34,
}
h := 25
reflectFn(a)
reflectFn(b)
reflectFn(c)
reflectFn(d)
reflectFn(e)
reflectFn(f)
reflectFn(&h)
}
通过反射设置变量的值
47 Go语言 反射 反射的引出、反射获取变量类型变量值、反射修改变量值 | 32:47
package main
import (
"fmt"
"reflect"
)
func reflectSetValue(x interface{}) {
v := reflect.ValueOf(x)
// x.Elem获取指针变量的值
if v.Elem().Kind() == reflect.Int64 {
v.Elem().SetInt(120)
}
}
func main() {
var a int64 = 100
reflectSetValue(&a)
fmt.Println(a)
}
结构体反射
package main
import (
"fmt"
"reflect"
)
type student struct {
Name string `json:"name" from:"userName"`
Age int `json:"age"`
}
func test(x interface{}) {
t := reflect.TypeOf(x)
if t.Kind() != reflect.Struct && t.Elem().Kind() != reflect.Struct {
fmt.Println("不是结构体")
return
}
// Field就是结构体本身,按下标第几个排序,0就是获取的Name
field0 := t.Field(0) // {Name string json:"name" 0 [0] false}
fmt.Println(field0.Name)
fmt.Println(field0.Type)
fmt.Println(field0.Tag.Get("json"))
fmt.Println(field0.Tag.Get("from"))
// 通过字段名获取Field
field1, ok := t.FieldByName("Age")
if ok {
fmt.Println(field1.Name)
}
// 通过类型变量的NumField获取该结构体有几个字段
fmt.Println(t.NumField())
// 通过值变量获取结构体属性的值
v := reflect.ValueOf(x)
fmt.Println(v.FieldByName("Name"))
}
func main() {
stu1 := student{
Name: "张三",
Age: 13,
}
test(stu1)
}
结构体方法
package main
import (
"fmt"
"reflect"
)
type student struct {
Name string `json:"name" from:"userName"`
Age int `json:"age"`
}
func (s student) PrintInfo(prefix string) {
fmt.Println(prefix, s)
}
func (s *student) SetName(name string) {
s.Name = name
}
func test(x interface{}) {
//获取结构体方法
t := reflect.TypeOf(x)
if t.Kind() != reflect.Struct && t.Elem().Kind() != reflect.Struct {
fmt.Println("不是结构体")
return
}
// 通过类型变量的Method
method0 := t.Method(0) // 和结构体方法顺序没有关系,和A结构体方法的ASCII有关系
fmt.Println(method0.Name)
fmt.Println(method0.Type)
// 执行方法
v := reflect.ValueOf(x)
v.MethodByName("SetName").Call([]reflect.Value{reflect.ValueOf("李四")})
fmt.Println(v.Elem().FieldByName("Name"))
var params []reflect.Value
params = append(params, reflect.ValueOf("测试输出"))
v.MethodByName("PrintInfo").Call(params)
// 获取方法数量
fmt.Println(t.NumMethod())
}
func main() {
stu1 := student{
Name: "张三",
Age: 13,
}
test(&stu1)
}修改结构体属性
package main
import (
"fmt"
"reflect"
)
type student struct {
Name string `json:"name" from:"userName"`
Age int `json:"age"`
}
func test(x interface{}) {
t := reflect.TypeOf(x)
// 判断是否等于ptr类型,就是指针地址
if t.Kind() != reflect.Ptr {
fmt.Println("不是结构体指针")
return
} else if t.Elem().Kind() != reflect.Struct {
fmt.Println("不是结构体")
return
}
// 修改结构体的属性
v := reflect.ValueOf(x)
name := v.Elem().FieldByName("Name")
name.SetString("李四")
}
func main() {
stu1 := student{
Name: "张三",
Age: 13,
}
test(&stu1)
fmt.Println(stu1)
}
不要乱用反射,非常脆弱,不容易理解
文件目录操作
49 Go语言 文件 目录操作 读取文件 写入文件 | 13
读取文件
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
)
func main() {
// 以已读的方式打开文件
file1, err := os.Open("./test.txt")
defer file1.Close()
if err != nil {
fmt.Println(err)
return
}
// 读取文件方法1,使用read
fmt.Println("-----read方式读取")
var tempSlice = make([]byte, 16)
var strSlice []byte
for {
n, err := file1.Read(tempSlice)
if err == io.EOF {
break
}
if err != nil {
fmt.Println("文件读取失败")
return
}
strSlice = append(strSlice, tempSlice[:n]...)
}
fmt.Println(string(strSlice))
// 读取文件方法2,bufio读取文件
fmt.Println("-----bufio读取")
file2, err := os.Open("./test.txt")
defer file1.Close()
if err != nil {
fmt.Println(err)
return
}
var fileStr string
reader := bufio.NewReader(file2)
for {
str, err := reader.ReadString('\n') //表示一次读取一行
if err == io.EOF {
// 使用这种方式,还会有str,
fileStr += str
break
}
if err != nil {
fmt.Println(err)
return
}
fileStr += str
}
fmt.Println(fileStr)
// 使用ioutil读取
// 非常小才用,已弃用??
fmt.Println("-----ioutil读取")
byteStr, err := ioutil.ReadFile("./test.txt")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(byteStr))
}
文件写入
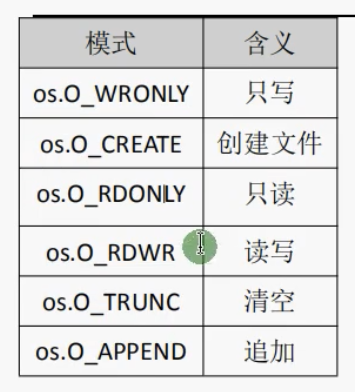

package main
import (
"bufio"
"fmt"
"io/ioutil"
"os"
)
func main() {
//方法1:write方法
file, err := os.OpenFile("./test1.txt", os.O_CREATE|os.O_RDWR|os.O_TRUNC, 0666)
defer file.Close()
if err != nil {
fmt.Println(err)
return
}
//写入文件
file.WriteString("直接写入字符串数据1\n")
//byte切片写入
var str = "写入byte切片\n"
file.Write([]byte(str))
//方法2:bufio写入
writer := bufio.NewWriter(file)
writer.WriteString("你好golang")
writer.Flush()
//方法3:ioutil
str1 := "hello ioutil"
ioutil.WriteFile("./test2.txt", []byte(str1), 0666)
}
目录创建
// 创建文件夹
os.Mkdir("./abc",0666)
// 创建多级目录
os.MkdirAll("./dir1/dir2/dir3",0666)删除文件和目录
// 删除一个文件或者文件夹
err := os.Remove("test.txt")
err := os.Remove("./test")
// 删除多级
err := os.RemoveAll("./dir")文件重命名
err := os.Rename("./test.txt","./newText.txt")